The Lazy (and Easy) Pre-Trained Translator of the Year


We made our own Neural Machine Translator (NMT) in 2019, which helped us to translate Dutch to English. Now it is 2022, and many things have changed in the world of Data Science. The arrival of Bidirectional Encoder Representations from Transformers (BERT), a pre-trained transformer model, in 2019 brought a new page for Natural Language Processing (NLP). And nowadays we have Generative Pre-trained Transformer 3 (GPT-3), an even larger model than BERT with 175 billion(!) parameters. As technologies evolve day after day, we should take the advantage of the evolution. So our project this time is --- take a shortcut and use a pre-trained model to build our translator.
Pick a Pre-Trained Model
We mentioned about BERT is the new gold standard of Data Science, then can we use it as our pre-trained translator model? Well, BERT is good, but it is not a good translation model. BERT is a pre-trained model specialized in context word representation. i.e. It can tell the difference between "mouse" as a computer peripheral and a small mammal. But the way it trains the model using masked words may case problems in handling translation. There is a research paper on using BERT in neural translation, however, according to its content and setting, it is never the "lazy and easy" thing we wanted.

Then what about the all mighty GPT-3? Yes, GPT-3 can legitimately do everything, including translation. But then the problem is on our side. The place I am currently living in, Hong Kong, is one of the GPT-3 unsupported countries. There is a GPT-3 open source alternative, GPT-J, which contains 6 billion parameters as well. This powerful open source pre-trained model does need a little bit of time for setting it up. Thus it just violates our "lazy and easy" principle.
When one door closes, another opens. On the internet nowadays, there are always more doors than we expect. So we have Argos Translate, the OpenNMT and the SentencePiece powered open source translator. And you may notice, this Argos Translate is using the same tech stack we did last time for our own translator. This time, we can skip the training part and go straight for the translating part, easy peasy!
Never to the Training, just Straight to Results
Although we don't need a training in using Argos Translate, we do need an installation of the library :]]. Like we what did in past, we use pipenv to do the deployment job.
$pipenv --three
$pipenv shell
$pipenv install argostranslateOkay, we are good to go. We are CodeAStar, let's do what we do best here --- code!
WAIT!
In order to become a good developer, please always remember, design first before you code. So we have the following sequence diagram:
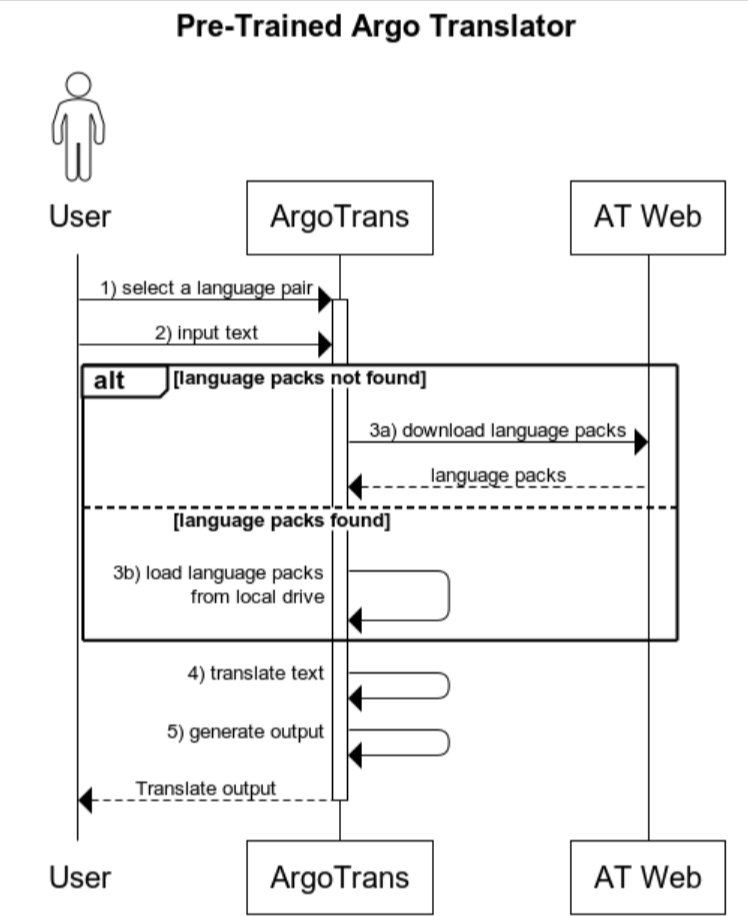
The translation flow is straight forward. But there are somethings we can find out from the diagram:
- we need to provide a way for a user to enter the translation language pair, e.g. from GUI(Graphical User Interface) or command line arguments
- the application should allow a user to submit input through GUI or command line interface
- the internet connection is required, otherwise we have to download language packages to local drive first
- like the input, the application should present the translated outcome in different ways, like GUI, file output or console output.
When we clean up those design considerations, finally, we are starting to work.
EZ coding for the pre-trained translator
When we say "EZ coding", it always comes easy with an easy interface. So we are building the pre-trained translator with the command line interface. i.e.
$python ez_trans.py <FROM LANG> <TO LANG> <INPUT FILE>And we should add some code to handle the command line arguments and we have argparse - the Python bundled arguments handler.
import argparse
from argostranslate import package, translate
parser = argparse.ArgumentParser()
parser.add_argument("from_lang", help = "From Language, e.g. en")
parser.add_argument("to_lang", help = "To Language, e.g. es")
parser.add_argument("input_file", help = "Input Text File, e.g. abc.txt")
args = parser.parse_args()After getting the user inputs, it is time for us to get the pre-trained language models from Argo Translate.
try:
print("Getting the ArgosTranslate package index...")
available_packages = package.get_available_packages()
except:
package.update_package_index()
available_packages = package.get_available_packages()
try:
selected_package = list(
filter(
lambda x: x.from_code == args.from_lang and x.to_code == args.to_lang, available_packages
))[0]
except:
print(f"Error for finding language pair for [{args.from_lang}] to [{args.to_lang}]")
exit()
print(f"Download '{selected_package}' model from the ArgosTrans if no model is found in the current system...")
download_path = selected_package.download()
package.install_from_path(download_path)
installed_languages = translate.get_installed_languages()
argo_from_lang = list(filter(lambda x: x.code == args.from_lang,installed_languages))[0]
argo_to_lang = list(filter(lambda x: x.code == args.to_lang,installed_languages))[0]
translation = argo_from_lang.get_translation(argo_to_lang)
translated_lines = []Then we have only few things left: open the input file, translate it line by line with Argo Translate and save to the output file. Since we are working on foreign languages, remember to add "encoding='utf8'" from the "open(....)" command.
print(f"Reading '{args.input_file}' and starting to translate...")
#load text from file
with open(args.input_file, encoding='utf8') as f:
lines = f.read().splitlines()
for l in lines:
translated_l = translation.translate(l)
translated_lines.append(translated_l)
translated_output = '\n'.join(translated_lines)
#save our translated result into a file
with open("output_"+args.input_file,'w',encoding='utf8') as o:
o.write(translated_output)
print(f"Translated output is saved as 'output_{args.input_file}', enjoy!")Our EZ pre-trained translator is done! See? The lines of code, including comments, are just under 50!
Test Drive on the Pre-Trained Translator
It is a tiny translator, but does size matter? Let's prove it. Since I am studying Portuguese (or Português), we will take the Portuguese from my text book and use our EZ translator to translate it back to English. Then we can see if it is well matched to the actual translation.
Here is our input:
Afonso: Olá! Eu chamo-me Afonso. E você, como é que se chama?
Russell: Olá! Eu sou o Russell.
Afonso: De onde é?
Russell: Sou da Austrália, de Darwin. E vocé?
Afonso: Eu sou Portugal, de Évora. Que línguas fala?
Russell: Falo inglês, alemão e um pouco de português.
Afonso: Eu falo português, cantonês, inglês e um pouco de mandarim.
This is a conversation between two men, Afonso and Russell, introducing each other and asking what languages they can speak.
What we do next is, save the conversation into a file then run our EZ translator for Portuguese (pt) to English (en) translation.
$python ez_trans.py pt en pt_test.txtAnd we get the output file as:
Afonso: Hello! My name is Afonso. What's your name?
Russell: Hello! I'm Russell.
Afonso: Where are you from?
Russell: I'm from Australia, from Darwin. And you?
Afonso: I'm Portual from Évora. What languages do you speak?
Russell: I speak English, German and a little Portuguese.
Afonso: I speak Portuguese, Cantonese, English and a little Mandarin.
This is exactly what are they talking about. Therefore our tiny EZ translator does score big in the translation task. Maybe I am taking the elementary course, thus the conversation piece is a bit simple and straight-forward for our EZ translator. Overall, it is a tiny, fast and accurate machine translator.
What have we learned in this post?
- Life is short, if there is something we can use, just use it, don't reinvent the wheel
- Always design first code later
- The use of Argo Translate
- Size doesn't matter in the world of coding
(the complete source package can be found at GitHub: https://github.com/codeastar/lazy_transator)



