"Do you have a dog?" explained in Machine Learning


You have probably read the above comic in 9gag or imgur before. It is a funny joke, but on the other hand, it is also a material for our Machine Learning topic. It sounds weird? Oh yeah, sometimes knowledge comes from strange ideas.
The Comic
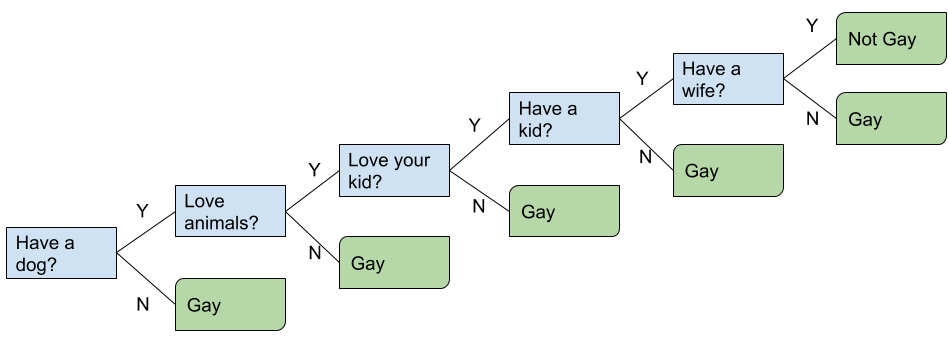
Here is the comic, for people who have not read it before. If you have read it or just tl;dr, we can go to the analysis section after the comic.

The Analysis
From our first ever Data Science post in this blog, we know that Data Science is all about solving problems. In the comic, the problem that the bartender trying to solve was: see rather someone is gay or not.
Since the bartender would predict the outcome, he was a learning model there. A learning model needed to be trained, so he met his training dataset, a consultant in his bar. After a brief training session with the consultant, he made a prediction using his testing dataset, a new customer in his bar. Then we found three major machine learning components in the comic: a learning model (the bartender), a training dataset (the consultant, the "logic" thinker) and a testing dataset (a new customer in red shirt). And then, a disaster just happened.

The Problem
The bartender model made a groundless prediction. We found that the bartender model was underfitting. As it had a limited training dataset with few features.

At the end, the bartender became a weak learner, i.e. a model with high bias and low variance, which hardly made a accurate prediction.
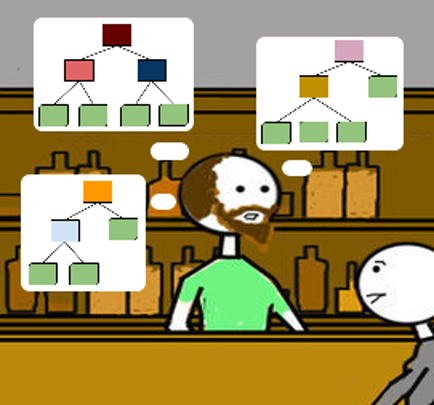
The Action
In order to improve the learning model, we can increase the number of records and features in training dataset.

Thus the model can have more data to build more decision trees and increase its variance.
Then the learning model can verify its accuracy by cross validation with training dataset.

Other than using a single model, we can ensemble the prediction from the learning model with other trained models. So we can have a better result with higher variance.

After applying above improvements, we can have a better model again!
Well, although the bartender model just sounds laughable, there is a study from Stanford University using deep neural networks to do the 'gay test' in real life as well.



