How to choose a machine learning model in Python?


Do you feel excited? Yeah, we should! But we have also omitted several details on the Data Science Life Cycle. Do you remember why I picked Support Vector Machine as our machine learning model last time? I give you 3 seconds to answer.
3......
2.....
1...
I choose Support Vector Machine, SVC(), as our model, as it is shorter to type for our tutorial ( :]] ) .
Yes, it is for tutorial purpose only. If you try to answer like that to your employer or client in real life, well, you might be fired or kicked by them. (Again, don't try this at work!)
The proper way to pick a model
A good model in data science is the model which can provide more accurate predictions. In order to find a accurate model, the most popular technique is using k-fold cross validation.
K-fold cross validation is the way to split our sample data into number(the k) of testing sets. And K testing sets cover all samples in our data. The validation process runs K times, on each time, it validates one testing set with training data set gathered from K-1 samples. Thus all data is used for testing and training, and each data has been tested exactly once.
K-fold cross validation in action
Let's use our Iris data set as an example:
import pandas as pd
import numpy as np
from sklearn import model_selection
df = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/bezdekIris.data",
names = ["Sepal Length", "Sepal Width", "Petal Length", "Petal Width", "Class"])
#shuffle our data and we use 121 out of 150 as training data
data_array = df.values
np.random.shuffle(data_array)
X_learning = data_array[:121][:,0:4]
Y_learning = data_array[:121][:,4]
#split our data in 10 folds
kfold = model_selection.KFold(n_splits=10)In Python, K-fold cross validation can be done using model_selection.KFold() from sklearn. We take 121 records as our sample data and splits it into 10 folds as kfold.
So what is inside the kfold? We can examine the kfold content by typing:
for train_index, test_index in kfold.split(X_learning):
print("Train Index:")
print(train_index)
print("Test Index:")
print(test_index)Below are the first 2 folds of the kfold:
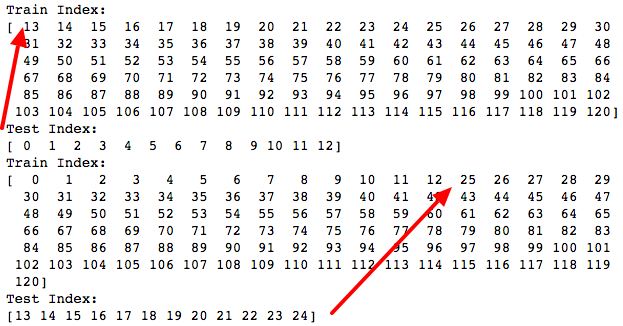
We can notice that a testing set is excluded from a training set on each fold, then the previous testing set would be put back in the next training set and a new training set is used. At the end of 10 folds, all data would be used as training data set and be a testing data set once.
Now we have k-fold of data set (actually 10 folds, if you ask). It it the time to test our models. Then, another problem has arisen.
Which machine learning models should we choose?
Luckily there is a cheat sheet from Scikit Learn to save our day:
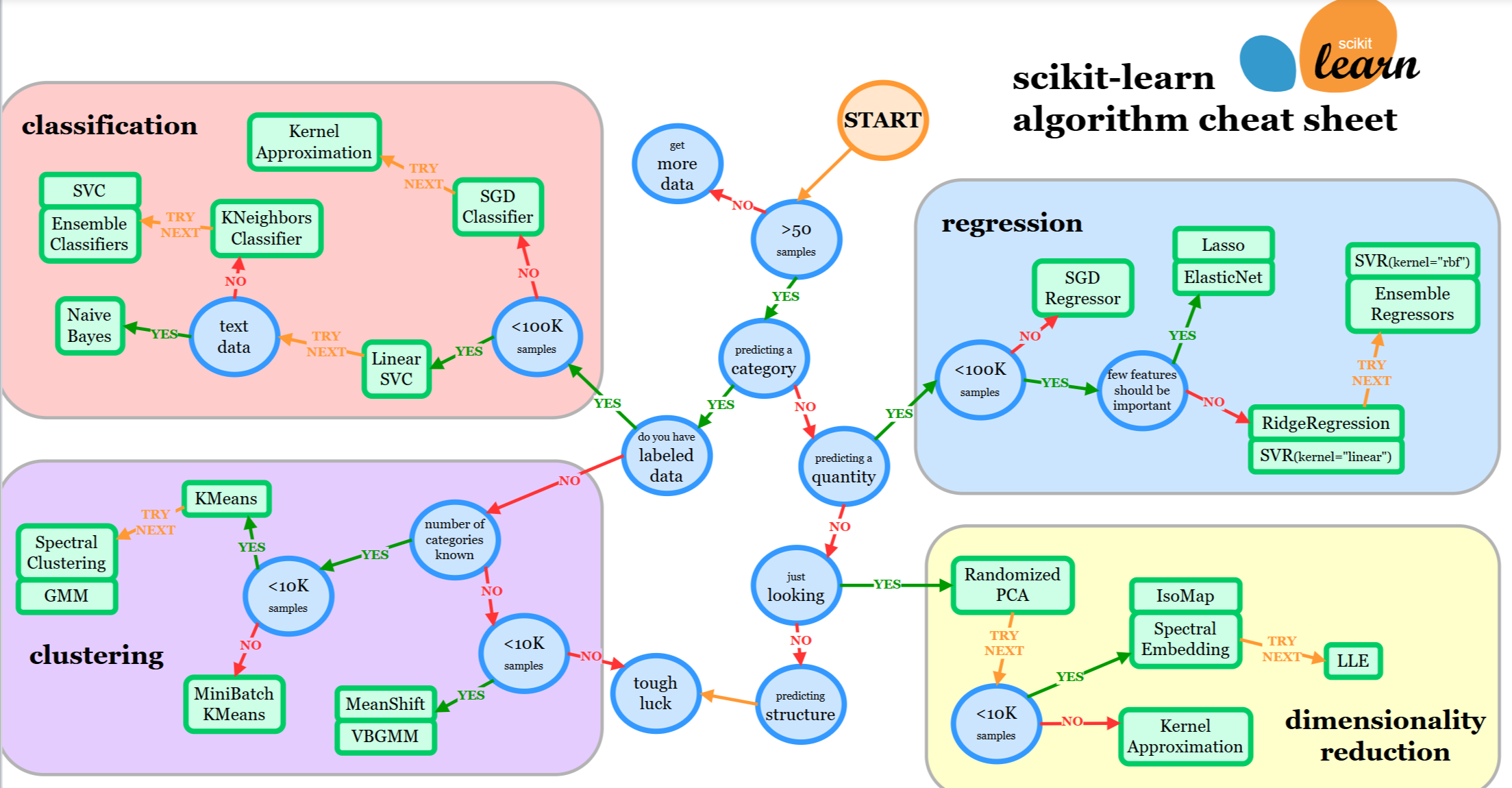
(source: https://scikit-learn.org/stable/machine_learning_map.html)
For our Iris class data science project, we teach a computer with data-real life relationships. And the computer makes certain decisions because it is taught to do so. We call this as supervised learning.
In Sciki Learn library, we pick some typical models from its supervised learning list:
- Logistic Regression (LoR)
- Linear Discriminant Analysis (LDA)
- Quadratic Discriminant Analysis (QDA)
- Support Vector Classification (SVC)
- Linear SVC (LSVC)
- Stochastic Gradient Descent (SGD)
- K-Nearest Neighbors Classifier (KNN)
- Gaussian Naive Bayes (GNB)
- Decision Tree Classifier (DT)
- Random Forest Classifier (RF)
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.svm import SVC
from sklearn.svm import LinearSVC
from sklearn.linear_model import SGDClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifierPut them in our model array.
models = []
models.append(("LoR", LogisticRegression()) )
models.append(("LDA", LinearDiscriminantAnalysis()) )
models.append(("QDA", QuadraticDiscriminantAnalysis()) )
models.append(("SVC", SVC()) )
models.append(("LSVC", LinearSVC()) )
models.append(("SGD", SGDClassifier()) )
models.append(("KNN", KNeighborsClassifier()) )
models.append(("GNB", GaussianNB() ))
models.append(("DT", DecisionTreeClassifier()) )
models.append(("RF", RandomForestClassifier()) )And let computer calculate the k-fold cross validation score.
for name, model in models:
#cross validation among models, score based on accuracy
cv_results = model_selection.cross_val_score(model, X_learning, Y_learning, scoring='accuracy', cv=kfold )
print("\n"+name)
model_names.append(name)
print("Result: "+str(cv_results))
print("Mean: " + str(cv_results.mean()))
print("Standard Deviation: " + str(cv_results.std()))
means.append(cv_results.mean())
stds.append(cv_results.std())A result list like below would be shown, with each model's results, mean and stand deviation.

Since we have matpotlib, we can use it to visualize the k-fold cross validation results.
x_loc = np.arange(len(models))
width = 0.5
models_graph = plt.bar(x_loc, means, width, yerr=stds)
plt.ylabel('Accuracy')
plt.title('Scores by models')
plt.xticks(x_loc, model_names) # models name on x-axis
#add valve on the top of every bar
def addLabel(rects):
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width()/2., 1.05*height,
'%f' % height, ha='center',
va='bottom')
addLabel(models_graph)
plt.show()Then we can get a graph like below:
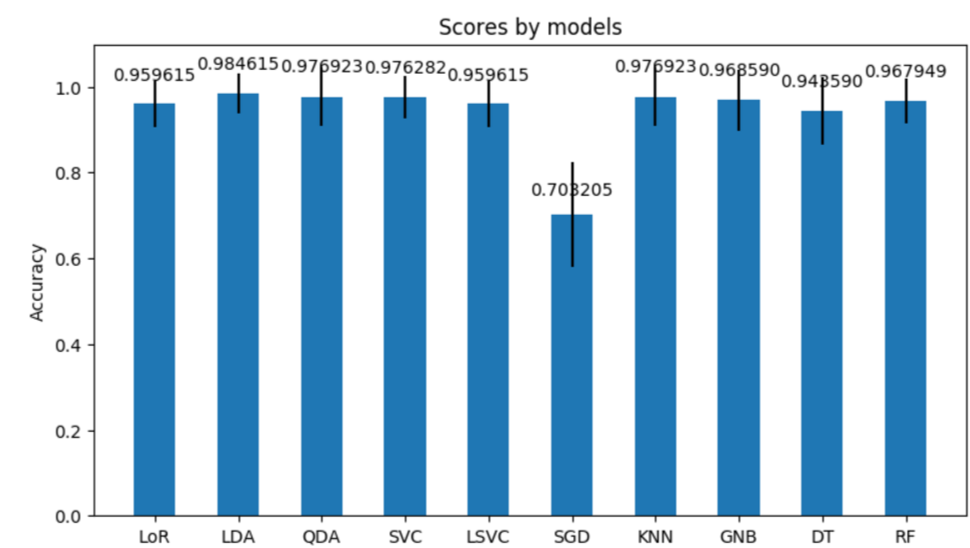
I blindly picked SVC as our learning model last time, but according to the scoring, it is not bad for the Iris classification actually.
Finding the model
Models scoring will be different based on sample size and feature size of your data. So the point of k-fold cross validation is not to find an all-time ultimate model, but a suitable model for your current data set.
The complete source can be found at https://github.com/codeastar/python_data_science_tutorial .



