Tutorial: How to do web scraping in Python?


When we go for data science projects, like the Titanic Survivors and Iowa House Prices projects, we need data sets to process our predictions. In above cases, those data sets have already been collected and prepared. We only need to download the data set files then start our projects. But when we want to work for our own data science projects, we need to prepare data sets ourselves. It would be easy if we can find free and public data sets from UCI Machine Learning Repository or Kaggle Data Sets. But, what If there is no suitable data set found? Don't worry, let's create one for ourselves, by web scraping.
Tools for Web Scraping: Scrapy vs Beautiful Soup
There are plenty of choices for web scraping tools on the internet. Since we have used Python for most of our projects here, we will focus on a Python one: Scrapy. Then it comes another debate topic, "Why don't you use Beautiful Soup, when Beautiful Soup can do the web scraping task as well?"
Yes, both Scrapy and Beautiful Soup can do the web scraping job. It all depends on how you want to scrape the data from the internet. Scrapy is a web scraping framework while Beautiful Soup is a library. You can use Scrapy to create bots (spiders) to crawl web content alone, and you can import Beautiful Soup in your code to work with other libraries (e.g. requests) for web scraping. Scrapy provides you a complete solution. On the other hand, Beautiful Soup can be quick and handy. When you try to scrape massive data or multiple pages from a web site, Scrapy would be your choice. If you just want to scrape certain elements from a page, Beautiful Soup can bring you what you wanted.
We can visualize the differences between Scrapy and Beautiful Soup in following pictures:



Web Scraping in Action
In this post, we are going to do a web scraping demonstration on eBay Daily Deals. We can expect we scrape around 3000 eBay items a time from the daily deals main page, plus its linked category pages.
Since we are scraping 3000 items from eBay Daily Deals, we will use Scrapy as our scraping tool. First thing first, let's get Scrapy to our environment with our good old pip command.
pip install Scrapy
Once Scrapy is installed we can run following command to get our scraping files framework (or, spider egg sac!)
scrapy startproject ebaybd
The "ebaybd" is our project/spider name and the startproject keyword will create our spider egg sac files framework with following content:
ebaybd/ # our project folder scrapy.cfg # scrapy configuration file (just leave it there, we won't touch it) ebaybd/ # project's Python module (there is where we code our spider) items.py # project items definition file (the item we ask our spider to scrape) pipelines.py # project pipelines file (the process we let our spider do after getting the item) settings.py # project settings file spiders/ # our spider folder (the place where we code our core logic)
Are you ready? Let's hatch a spider!
eBay Daily Deals spider hatching
First, we go to edit the items.py file, as we need to tell our spider what to scrape for us. We then create the EBayItem class and add our desired eBay fields there. class EBayItem(scrapy.Item): name = scrapy.Field() category = scrapy.Field() link = scrapy.Field() img_path = scrapy.Field() currency = scrapy.Field() price = scrapy.Field() orignal_price = scrapy.Field() Second, we need to tell our spider what to do once it has scrapped the data we wanted. So we edit the pipelines.py file with following content: import csv
class EBayBDPipeline(object):
def open_spider(self, spider):
self.file = csv.writer(open(spider.file_name, 'w', newline='', encoding = 'utf8') )
fieldnames = ['Item_name', 'Category', 'Link', 'Image_path', 'Curreny', 'Price', 'Original_price']
self.file.writerow(fieldnames)
def process_item(self, item, spider):
self.file.writerow([item['name'], item['category'],item['link'],
item['img_path'] , item['currency'],item['price'],
item['orignal_price']])
return item
We create an EBayBDPipeline class to ask the spider saving scraped data into a CSV file. Although Scrapy has its built-in CSV exporter, making our own exporter can provide better customization.
We have our scraped item class and the scraper pipline class, then we need to connect two classes together. So we work on the settings.py file by adding:
ITEM_PIPELINES = { 'ebaybd.pipelines.EBayBDPipeline': 300 }
It will tell our spider to run the EBayBDPipeline class after scraping an item. The number 300 after the pipeline class is the value to determinate the processing sequence in multiple pipeline environment. The value can be ranged from 0 - 1000, since we only have one pipeline class in this project, the value can be ignored here.
Build a Spider
After setting up those item and pipeline classes, it is time for our main event --- build a spider. We create a spider file, ebay_deals_spider.py, in our "spiders" folder: ebaybd/ ebaybd/ spiders/ ebay_deals_spider.py #our newly created spider core logic file Inside the spider file, we import required classes/modules. import scrapy from scrapy.http import HtmlResponse #Scrapy's html response class import json, re, datetime #for json, regular expression and date time functions from ebaybd.items import EBayItem #the item class we created in items.py Add a function to remove currency and thousand separator from scraped item price. def formatPrice(price, currency): if price is None: return None
price = price.replace(currency, "")
price = price.replace(",", "")
price = price.strip()
return price
And add a function to scrape html content into our EBayItem class. def getItemInfo(htmlResponse, category): eBayItem = EBayItem()
name = htmlResponse.css(".ebayui-ellipsis-2::text").extract_first()
if name is None:
name = htmlResponse.css(".ebayui-ellipsis-3::text").extract_first()
link = htmlResponse.css("h3.dne-itemtile-title.ellipse-2 a::attr(href)").extract_first()
if link is None:
link = htmlResponse.css("h3.dne-itemtile-title.ellipse-3 a::attr(href)").extract_first()
eBayItem['name'] = name
eBayItem['category'] = category
eBayItem['link'] = link
eBayItem['img_path'] = htmlResponse.css("div.slashui-image-cntr img::attr(src)").extract_first()
currency = htmlResponse.css(".dne-itemtile-price meta::attr(content)").extract_first()
if currency is None:
currency = htmlResponse.css(".dne-itemtile-original-price span::text").extract_first()[:3]
eBayItem['currency'] = currency
eBayItem['price'] = formatPrice(htmlResponse.css(".dne-itemtile-price span::text").extract_first(), currency)
eBayItem['orignal_price'] = formatPrice(htmlResponse.css(".dne-itemtile-original-price span::text").extract_first(), currency)
return eBayItem
We use Scrapy' selectors to extract data with the same CSS expressions. For example, we scrape an item name with: name = htmlResponse.css(".ebayui-ellipsis-2::text").extract_first()That means we scrape the text of the first element with "ebayui-ellipsis-2" CSS class, as the item name. (You can use your browser, right click an eBay daily deals page, select "Inspect" to get following screen)
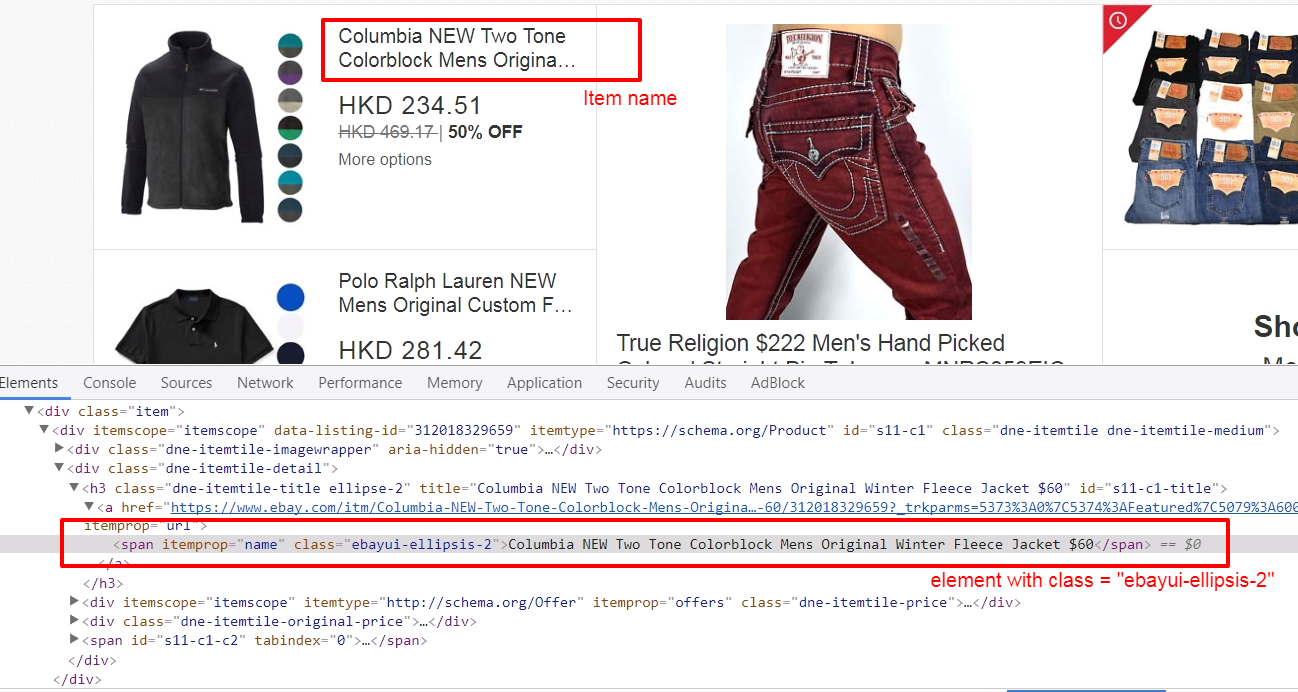
Inside the spider's brain
For our spider class, where we code the core logic, we have 2 major types of function, "start request" (start_requests) and "parse response" (parse and parse_cat_listing). class BDSpider(scrapy.Spider): name = "ebaybd" file_name = datetime.datetime.now().strftime("%F") +".csv" #use current date as file name
def start_requests(self):
...
def parse(self, response):
...
def parse_cat_listing(self, response):
...
The start_requests function is pretty straight forward, we tell our spider where (urls) to start scraping. def start_requests(self): urls = [ 'https://www.ebay.com/globaldeals' ] for url in urls: yield scrapy.Request(url=url, callback=self.parse) In our case, the global deals url (https://www.ebay.com/globaldeals) is used, thus people from anywhere, the US, Germany, India, South Korea, etc, can all get their eBay daily deals. After getting the url request, we ask the spider to parse the url content under the parse function. You may notice the keyword yield is used instead of return in the spider. Unlike the return keyword which sends back an entire list in memory at once. The yield keyword returns a generator object, which let the spider handle the parse request one by one. We will see more on the yield keyword in our parse function: def parse(self, response): #spotlight deals spl_deal = response.css(".ebayui-dne-summary-card.card.ebayui-dne-item-featured-card--topDeals") spl_title = spl_deal.css("h2 span::text").extract_first() eBayItem = getItemInfo(spl_deal, spl_title) yield eBayItem
#feature deals
feature_deal_title = response.css(".ebayui-dne-banner-text h2 span::text").extract_first()
feature_deals_card = response.css(".ebayui-dne-item-featured-card")
feature_deals = feature_deals_card.css(".col")
for feature in feature_deals:
eBayItem = getItemInfo(feature, feature_deal_title)
yield eBayItem
#card deals
cards = response.css(".ebayui-dne-item-pattern-card.ebayui-dne-item-pattern-card-no-padding")
for card in cards:
title = card.css("h2 span::text").extract_first()
more_link = card.css(".dne-show-more-link a::attr(href)").extract_first()
if more_link is not None:
cat_id = re.sub(r"^https://www.ebay.com/globaldeals/|featured/|/all$","",more_link)
cat_id = re.sub("/",",",cat_id)
cat_listing = "https://www.ebay.com/globaldeals/spoke/ajax/listings?_ofs=0&category_path_seo={}&deal_type=featured".format(cat_id)
request = scrapy.Request(cat_listing, callback=self.parse_cat_listing)
request.meta['category'] = title
request.meta['page_index'] = 1
request.meta['cat_id'] = cat_id
yield request
else:
self.log("Get item on page for {}".format(title))
category_deals = card.css(".item")
for c_item in category_deals:
eBayItem = getItemInfo(c_item, title)
yield eBayItem
When there is a spotlight deal, our spider will scrape the item and process the item pipeline task. The same workflow happens on featured deals. The difference is, there are more than one item in featured deals. Since we are using the yield keyword, we can call the item pipeline one by one without stopping the iteration.
Then on the category items, if there is a categorized daily deals link within the displayed categories, our spider will scrape daily deals items from the categorized page instead. And in those categorized daily deals pages, a tricky situation is happened there --- infinite scrolling.
Infinite Scroll Pagination Handling
The eBay categorized deals pages use infinite scrolling to display daily deals items. There is no "next" button for showing more items, the categorized deals page will display more items once a user has scrolled down the page a little bit. Since there is no pagination element on the page, we can not assign CSS or Xpath selector to our spider. But items do not come from no where, there should be somewhere to load new items. Infinite scrolling uses ajax to make it scroll infinity, so we should inspect the page's network performance. (Right click on your browser, select "Inspect" and click "Network" tab)
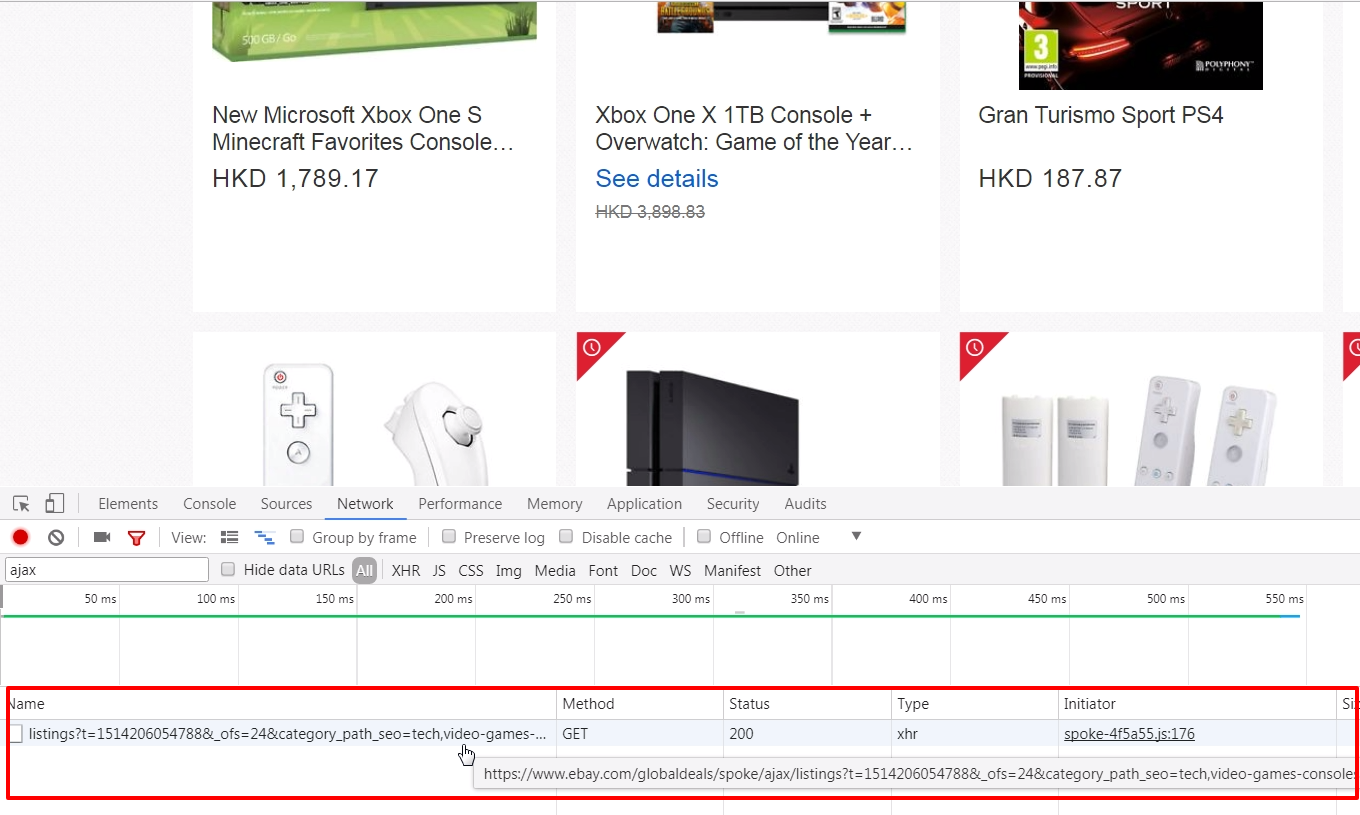
Try scrolling your page and see rather any JavaScript call is processed. And Ding! An ajax call to
https://www.ebay.com/globaldeals/spoke/ajax/listings is found. It will return 24 eBay items under a given category per call. We then request this JavaScript call and handle it in our other parse function, parse_cat_listing.Scrapy and JavaScript
The parse_cat_listing function is the place where we handle response from JavaScript and transform it into EBayItem.def parse_cat_listing(self, response): category = response.meta['category'] page_index = response.meta['page_index'] cat_id = response.meta['cat_id']
data = json.loads(response.body)
fulfillment_value = data.get('fulfillmentValue')
listing_html = fulfillment_value['listingsHtml']
is_last_page = fulfillment_value['pagination']['isLastPage']
json_response = HtmlResponse(url="json response", body=listing_html, encoding='utf-8')
items_on_cat = json_response.css(".col")
for item in items_on_cat:
eBayItem = getItemInfo(item, category)
yield eBayItem
if (is_last_page == False):
item_starting_index = page_index * 24
cat_listing = "https://www.ebay.com/globaldeals/spoke/ajax/listings?_ofs={}&category_path_seo={}&deal_type=featured".format(item_starting_index, cat_id)
request = scrapy.Request(cat_listing, callback=self.parse_cat_listing)
request.meta['category'] = category
request.meta['page_index'] = page_index+1
request.meta['cat_id'] = cat_id
yield request
Since the JavaScript returns a JSON object containing the item listing html content, we first obtain the html content in text. data = json.loads(response.body) fulfillment_value = data.get('fulfillmentValue') listing_html = fulfillment_value['listingsHtml'] Then use Scrapy's HtmlResponse class to encode the text to HTML. We apply UTF-8 encoding for cases with special characters appearing in an item name. json_response = HtmlResponse(url="json response", body=listing_html, encoding='utf-8') After that, we can apply the same getItemInfo logic we have done in the parse function.
As it is an infinite scrolling, we keep requesting the JavaScript call recurringly until the JSON object returns a last page flag.
The Scraping Result
We have set all our spider files, it is time to let it scrape by running following command: scrapy crawl ebaybd Our "ebaybd" spider then scrapes and saves the result in a "YYYY-MM-DD.csv" file. Below is the result I run with about 3000 records in 1 minute processing time.
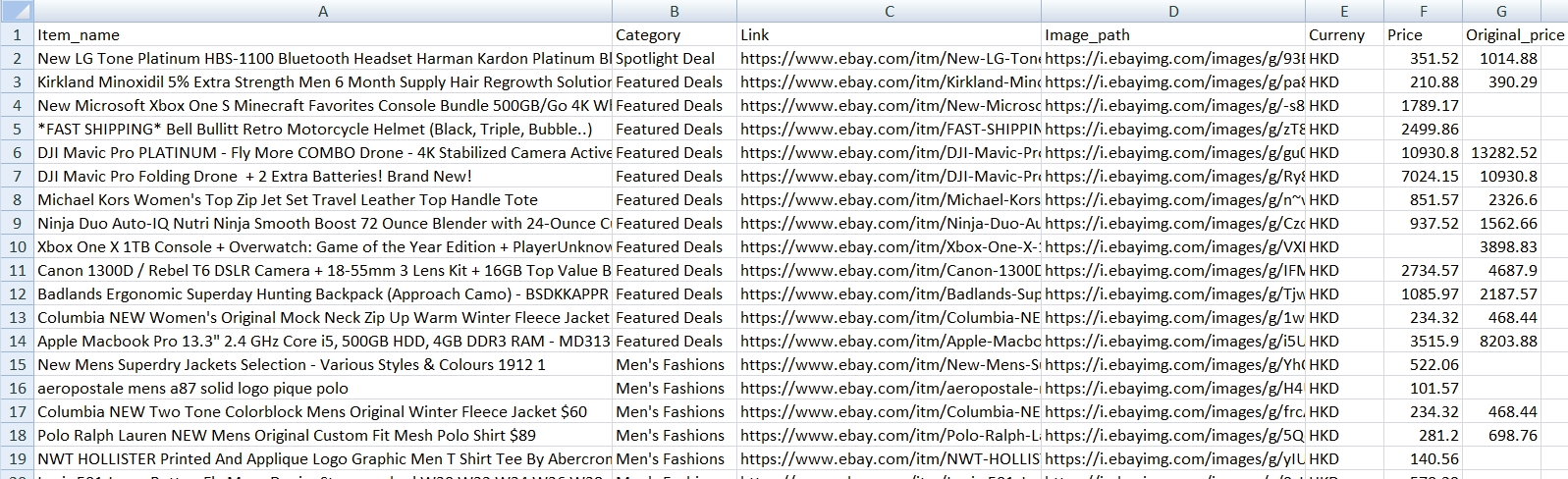
Our spider is done here, you may extend its functionality by scraping other categories / item attributes, or store the result in MongoDB, cloud service, etc. Happy Scraping!
What have we learnt in this post?
- Differences between Scrapy and BeautifulSoup
- Building our own Scrapy spider
- Using our own item pipeline processor
- Handling infinite scrolling
The source code package can be found at https://github.com/codeastar/ebay-daily-deals-scraper.



